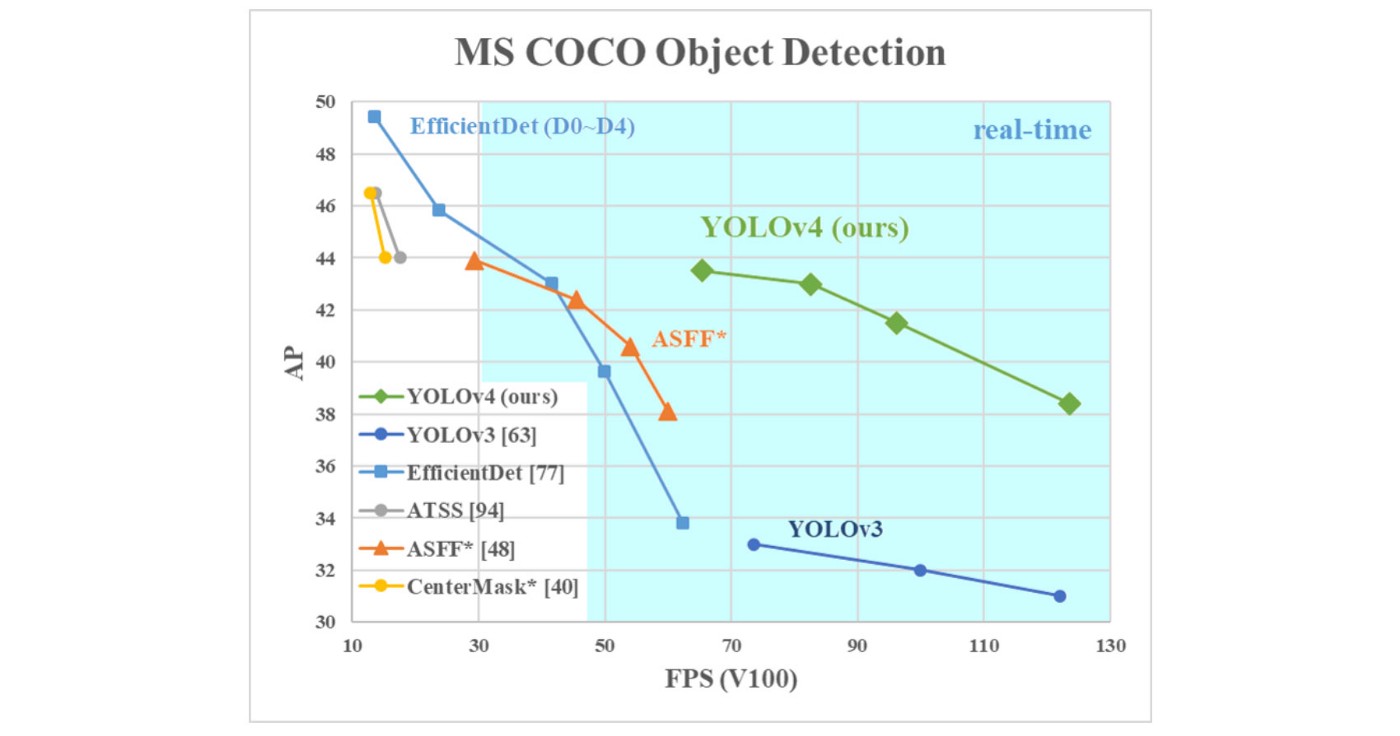
- Trong Yolov4, các tác giả tìm hiểu, thử nghiệm các phương pháp state-of-the-art trong object detection để đánh giá, so sánh sự hiệu quả của các phương pháp này theo một số tiêu chí cân bằng giữa độ phức tạp của mô hình và tốc độ xử lý FPS. Yolov4 cũng hướng tới khả năng training được trên một GPU.
- Kết quả: 43.5% AP (65.7% AP₅₀) trên tập dữ liệu MS COCO với tốc độ 65 FPS inference speed trên GPU Tesla V100.
Bag of Freebies vs Bag of Specials
- Bag of Freebies: Những phương pháp giúp cải thiện kết quả inference mà không làm ảnh hưởng tới tốc độ inference. Những phương pháp này thường là data augmentation, class imbalance, cost function, soft labeling, …
- Bag of Specials: Những phương pháp hi sinh một chút tốc độ inference mà làm cải thiện độ chính xác của model đáng kể. Những phương pháp này bao gồm tăng receptive field, sử dụng attention, feature intergration (kết hợp thông tin của các feature maps với nhau) như skip-connection & FPN (Feature Paramyd Network), hậu xử lý như NMS (Non Maximum Suppression).
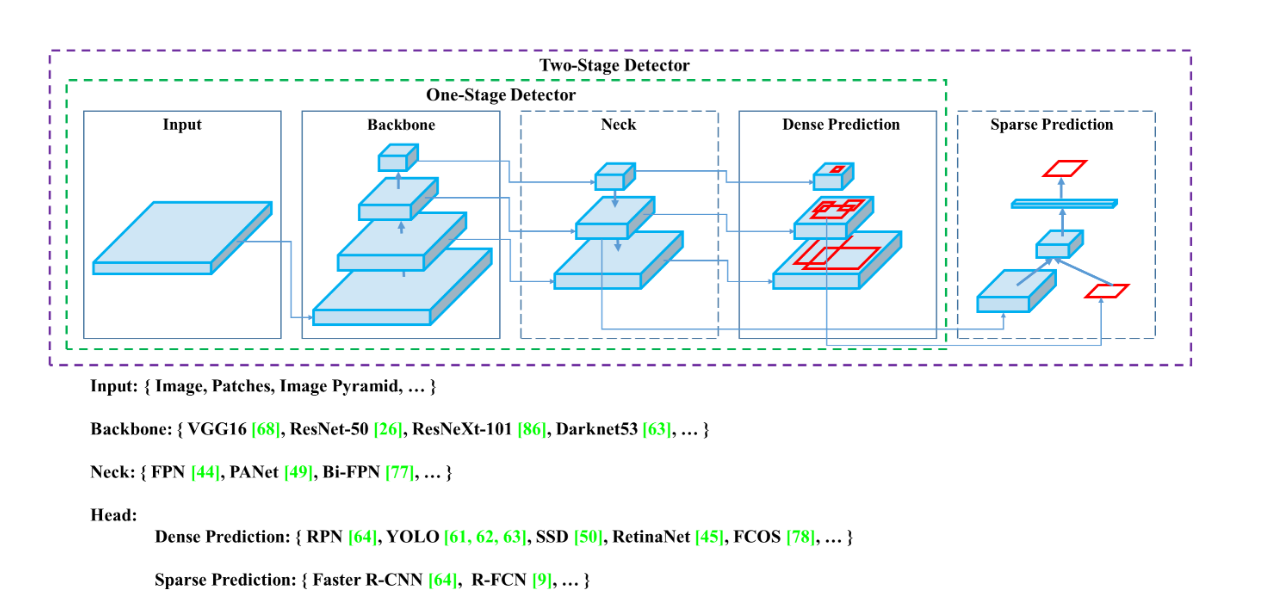
- Một mô hình object detection được cấu tạo bởi các thành phần:
- Input
- Backbone
- Neck
- Head
Backbone
Dense Block & DenseNet
- Để tăng độ chính xác của mô hình deep learning thì cách đầu tiên mà ta nghĩ tới là tăng độ phức tạp của mô hình, mà cụ thể là làm cho mô hình ngày càng sâu hơn. Tuy nhiên, việc này làm tăng độ phức tạp tính toán khi training, vì vậy, ta có thể áp dụng các kỹ thuật như skip-connection. Một kỹ thuật mở rộng của skip-connection là dense block.
- Dense block bao gồm nhiều lớp conv x(i) và H(i). Mỗi lớp H(i) bao gồm batch normalization, ReLU và theo sau bởi một conv layer. Các lớp H(i) này thay vì lấy input là output của layer ngay trước nó thì sẽ lấy tất cả các output của các layer trong dense block đó làm input.
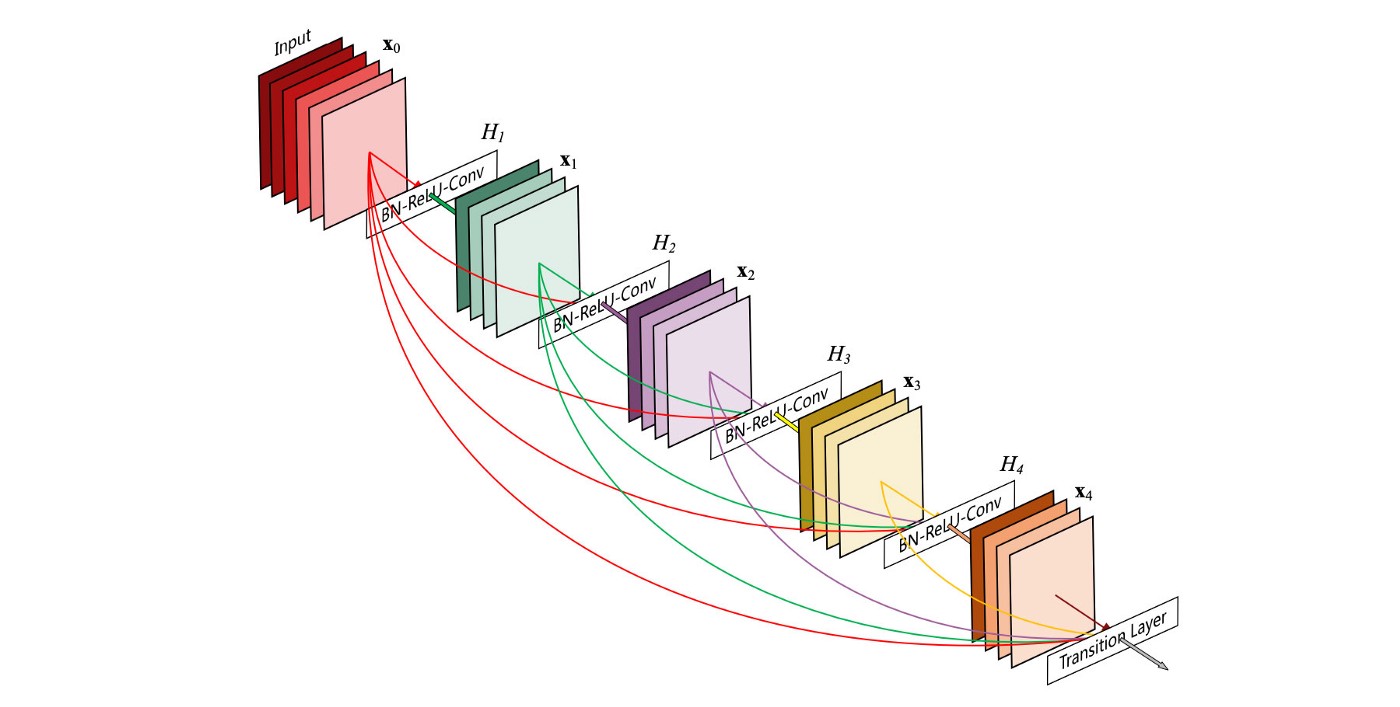
- Dense Net là sự kết hợp của các dense block và một transition layer ở giữa các dense block. Các transition layer này bao gồm một conv layer và một pool layer.

Cross-stage-partial-connection (CSP)
- CSPNet chia input feature map ra thành hai phần bằng nhau, một phần giữ nguyên để đưa vào transition block, phần còn lại được đưa vào 1 dense block + 1 transition layer. CSP connection giúp cho vừa lưu giữ được một phần thông tin từ các layer trước, vừa giảm độ phức tạp của mô hình.
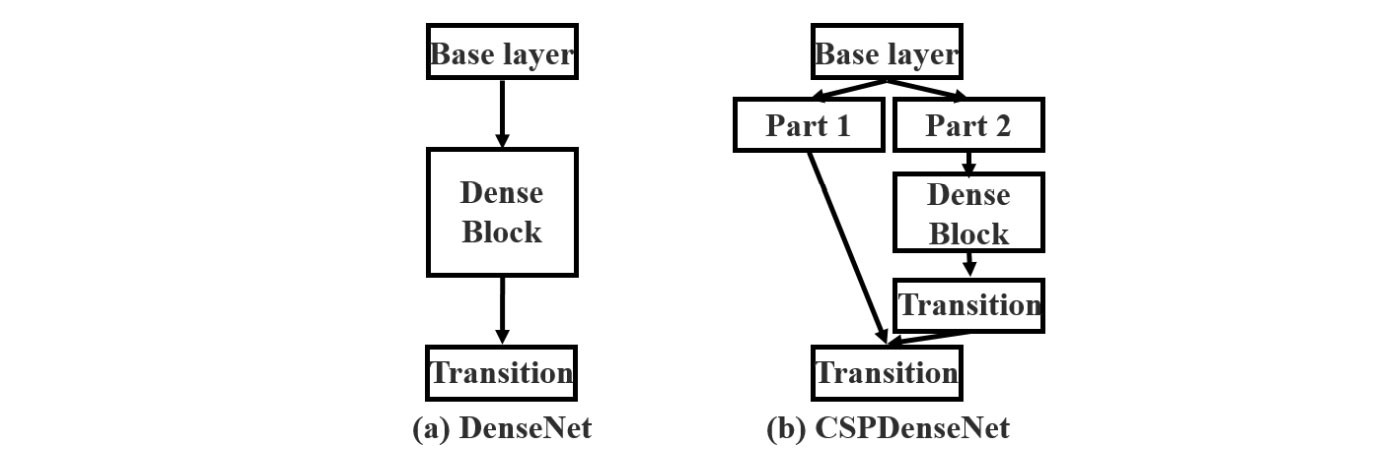

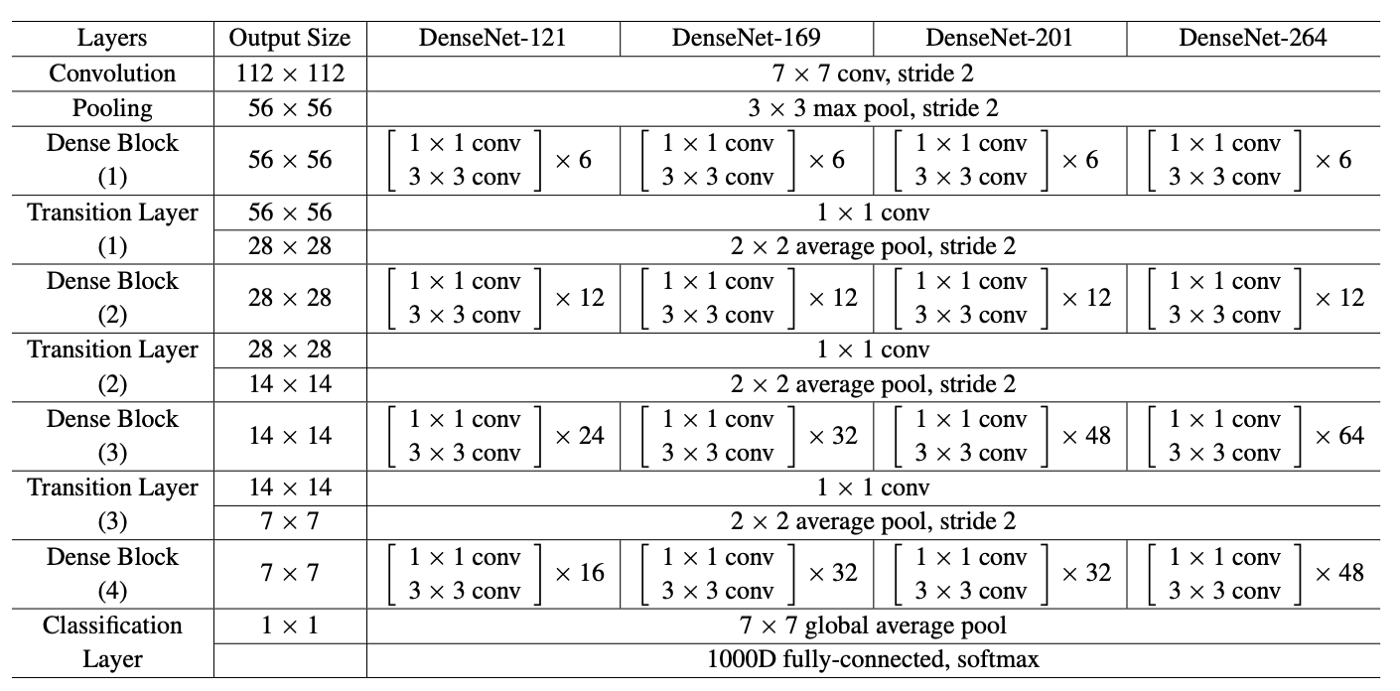
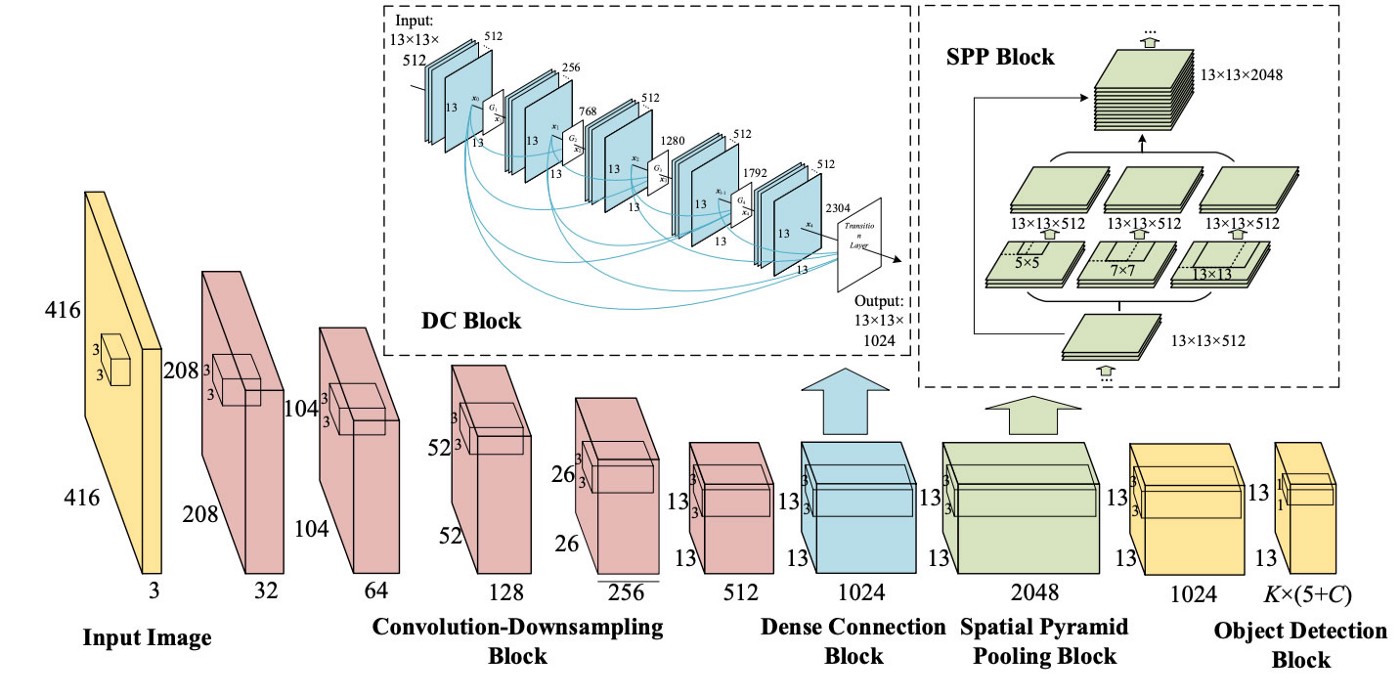
CSPDarknet53
- Yolov4 sử dụng CSPDarknet53 để làm backbone vì theo tác giả, CSPDarknet53 có độ chính xác trong task object detection cao hơn so với ResNet; và mặc dù ResNet có độ chính xác trong task classification cao hơn, hạn chế này có thể được cải thiện nhờ hàm activation Mish và một vài kỹ thuật sẽ được đề cập phía dưới.
Neck
- Một object detector bao gồm một backbone (feature extraction) và một head (obj detection). Để detect obj với các kích thước khác nhau, một kiến trúc mạng sử dụng các feature maps tại các vị trí khác nhau để predict.
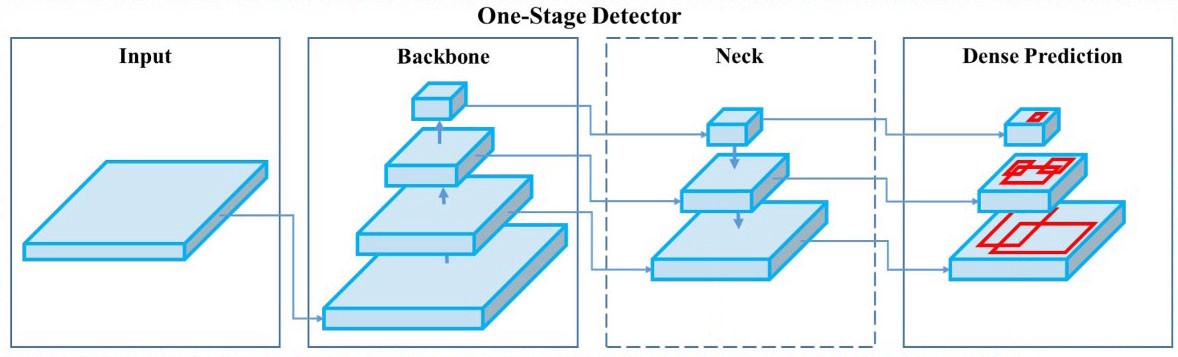
- Để làm giàu thông tin đẩy về head, một số feature map gần nhau trong bottom-up stream và top-down stream được kết hợp với nhau (element-wise/concatinate) trước khi đẩy vào head. Do đó, head sẽ có được rich spatial information từ bottom-up stream và rich semantic information từ top-down stream. Thành phần này được gọi là Neck.
Feature Pyramid Networks (FPN)
SPP (spatial pyramid pooling layer)
YOLO with SPP
- Từ Yolov3, các tác giả đã giới thiệu một cách thức áp dụng SPP (Yolov3-spp). Mạng SPP này được thay đổi, không còn là chia các feature map thành các bins rồi ghép các bins này với nhau để được một vector có dimension cố định nữa. Yolo-SPP áp dụng một maximum pool với các kernel kích thước khác nhau. Kích thước của input feature map được giữ nguyên, các feature map thu được từ việc áp dụng max pool (với kernel size khác nhau) sẽ được concatinate. Yolov4 cũng áp dụng lại kỹ thuật này.
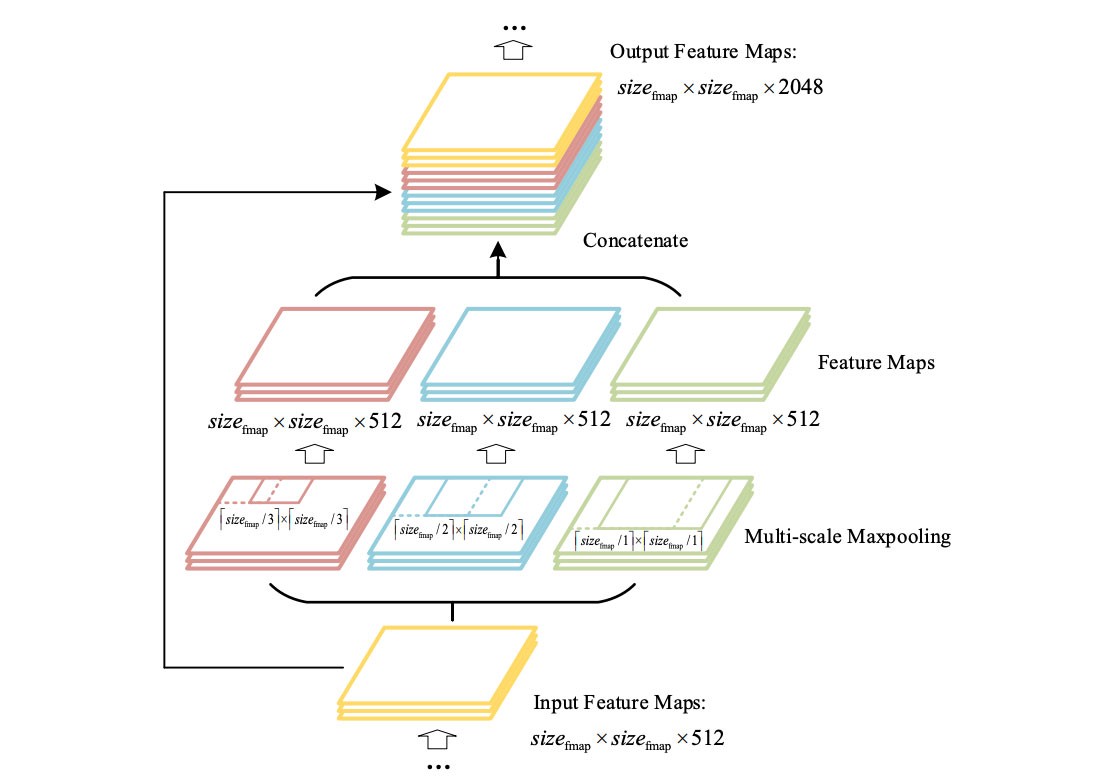
- Biểu đồ dưới đây mô tả việc áp dụng Yolo-SPP (bỏ qua phần DC Block)
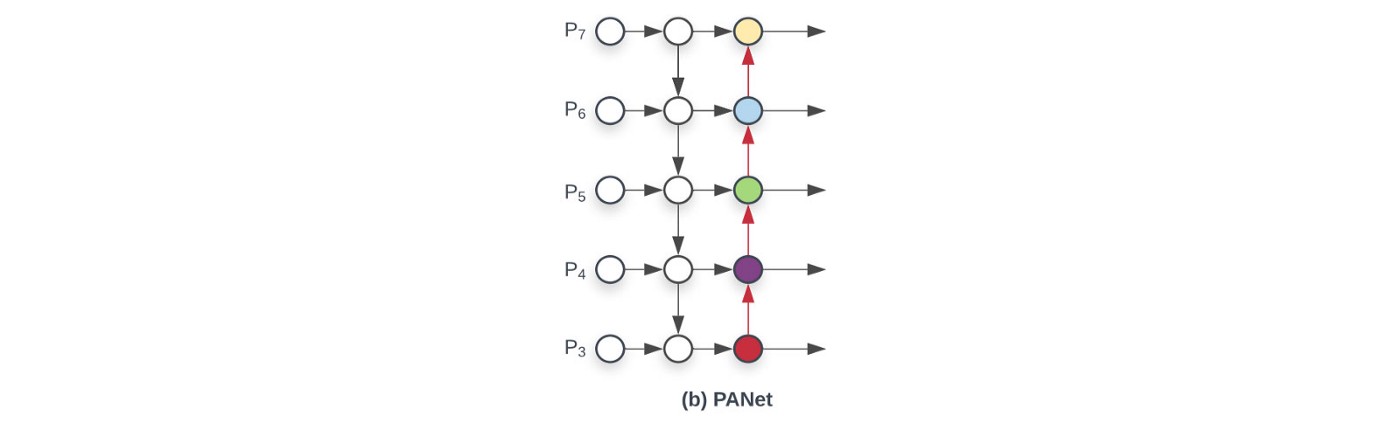
Path Aggregation Network (PAN) – ref
- Mạng DL càng sâu thì càng làm mất mát thông tin, do đó, để detect được các đối tượng có kích thước nhỏ, researchers đã đề xuất ra nhiều phương pháp như DenseBlock, FPN. PAN là một cải tiến của FPN nhằm cải thiện localized information trên các top layers.
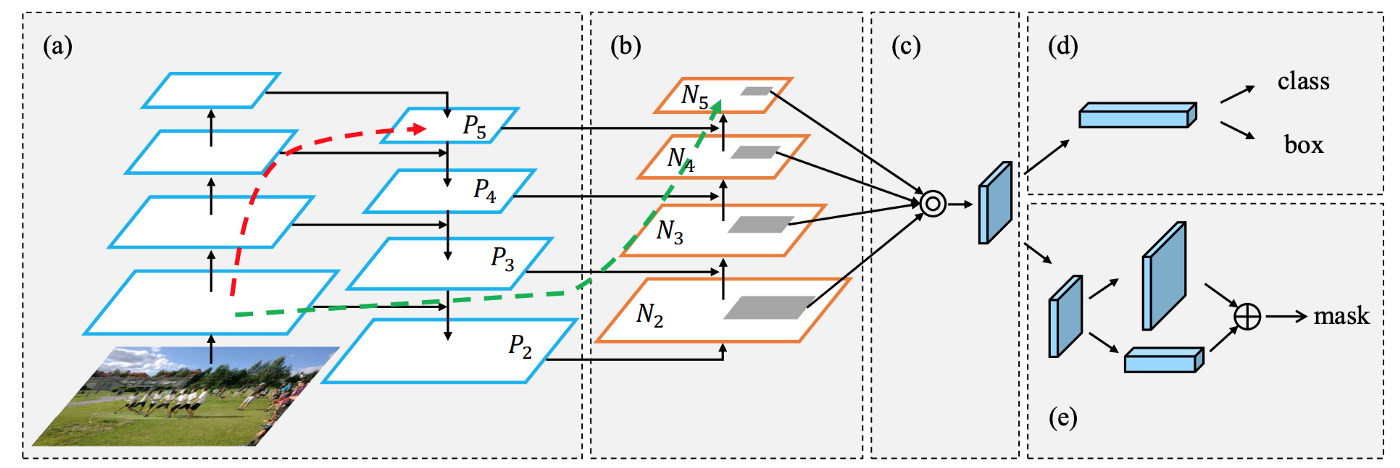
- PAN thêm 1 bottom-up pathway (b), trong đó, mỗi layer lấy input là feature maps của stage trước đó, đi qua một conv 3×3. Output được add với feature map của top-down pathway với stage tương ứng. Thiết kế của Neck có thể được mô tả như hình dưới:
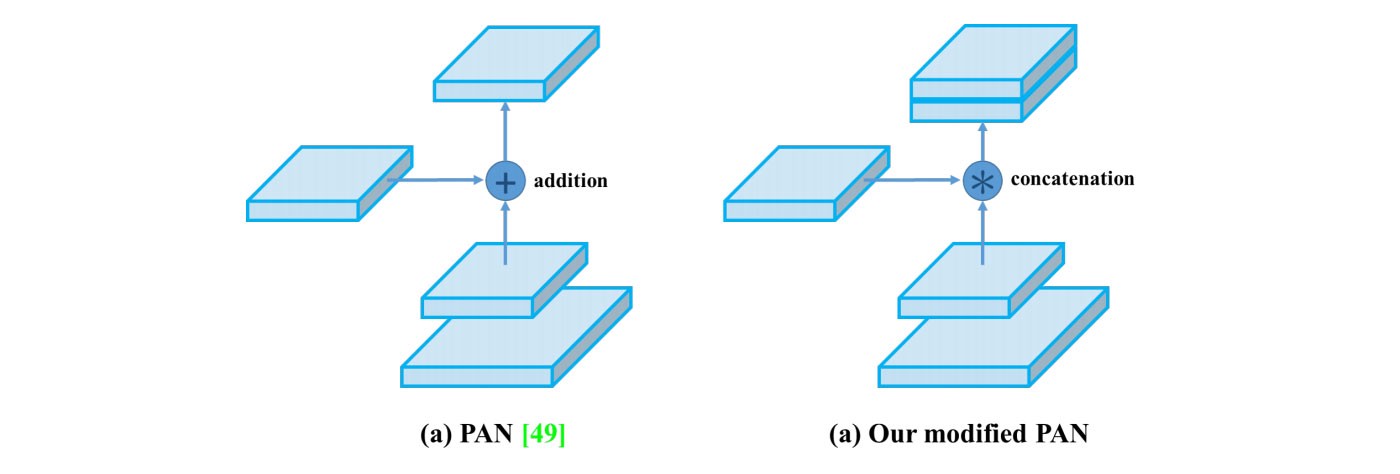
- Trong Yolov4, các tác giả chỉnh sửa hàm add thành hàm concat.
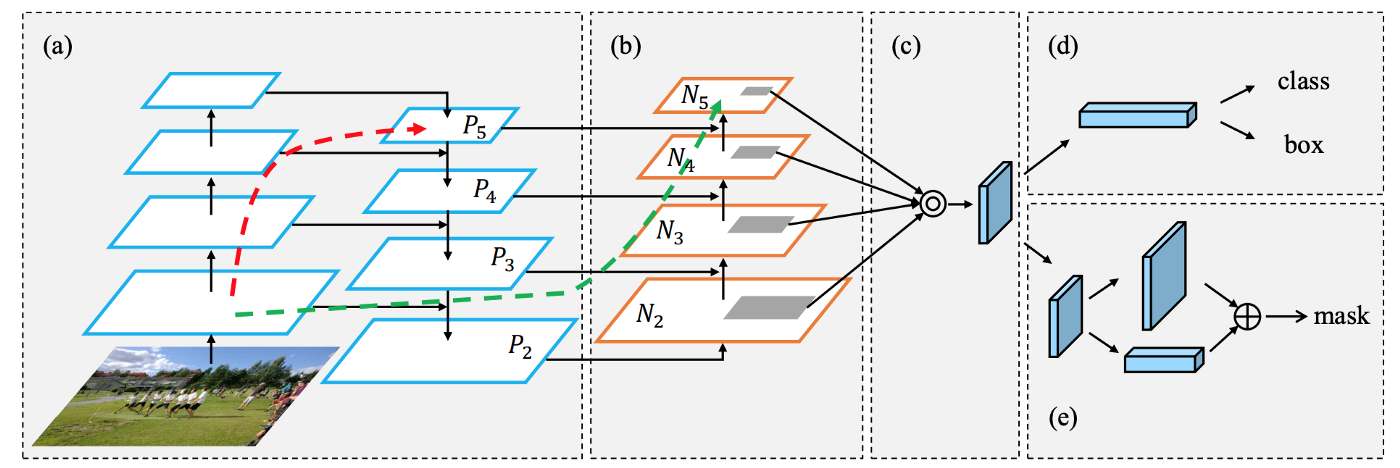
- Tại các các stage của augmented bottom-up pathway, object được detect một cách độc lập với các kích thước khác nhau. Điều này có thể dẫn tới sự dư thừa về dữ liệu hoặc tại mỗi stage sẽ không sử dụng thông tin từ các stage khác. Do đó, tại mỗi stage, các feature maps sẽ được đẩy qua một mạng SPP (=ROIAlign), rồi sau đó đưa qua lớp fully connected layer, kết quả thu được sau các lớp fully connected layer này sẽ được element-wise max operation để thu được prediction.
Spatial Attention Module (SAM)
- Áp dụng Attention vào model DL để xác định các thành phần/weights quan trọng.
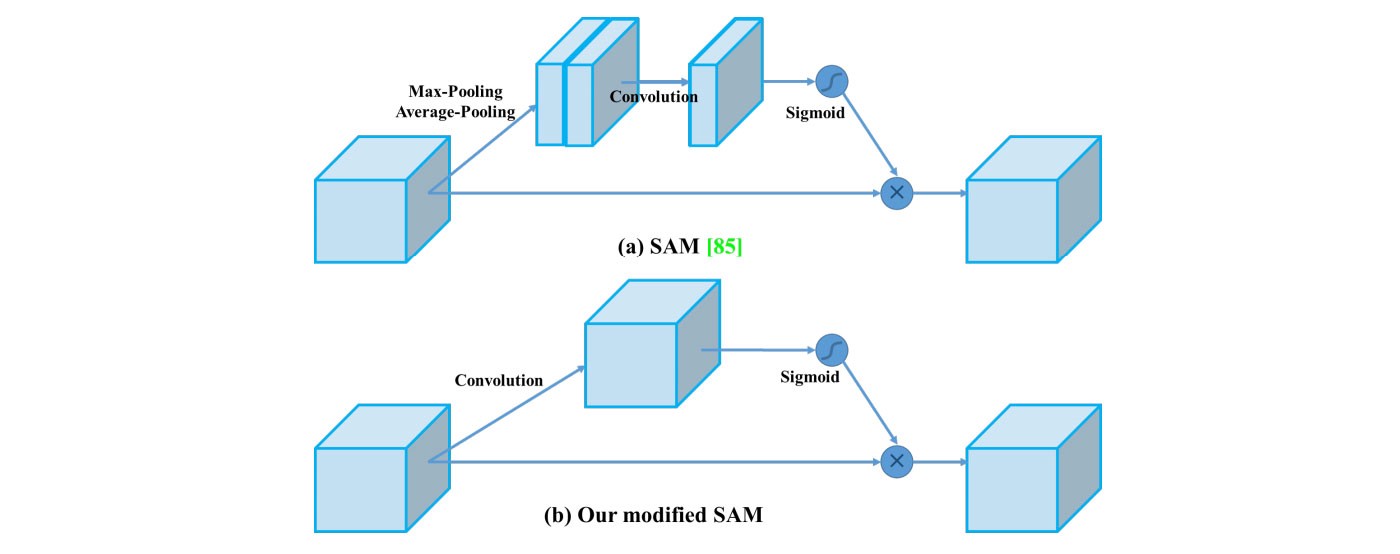
- Trong SAM, max pool & avg pool được thực hiện riêng biệt trên input feature maps để tạo thành hai tập feature maps. Hai tập này được đẩy vào conv layer, theo sau bởi một hàm sigmoid. Hàm sigmoid có vai trò đánh trọng số các weights của feature maps để tạo thành spatial attention layer.
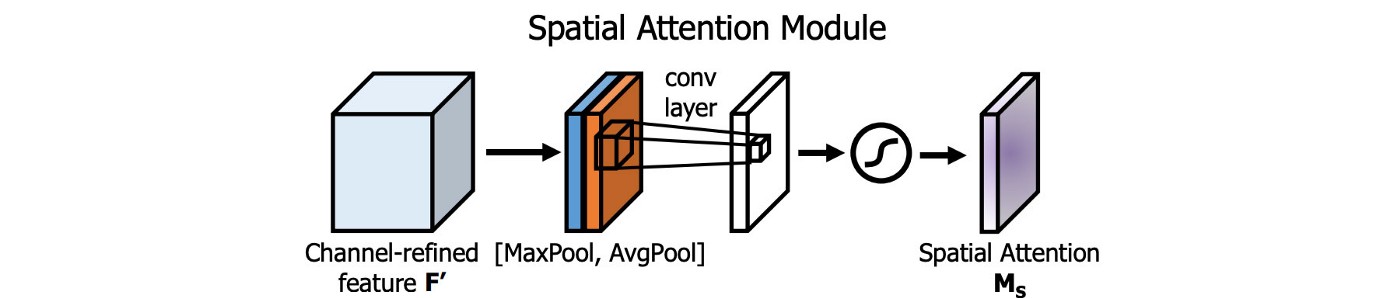
- Sau đó, lớp Spatial Attention layer này lại được apply vào input feature maps để thu được refined feature layer (tức các feature maps đã được đánh trọng số).
- Trong Yolov4, SAM được điều chỉnh không có hai lớp max pool, avg pool.
Yolov4 sử dụng gì?
Bag of Freebies cho backbone
- CutMix, Mosaic data augmentation
- DropBlock regulazation
- Class Label smoothing
1. CutMix data augmentation
- Dựa trên ý tưởng của CutOut: loại bỏ một vùng trên mỗi ảnh để model không thể overfit một feature đặc biệt nào đó trên tập training.
- Tuy nhiên, vùng ảnh bị loại bỏ được điền vào các giá trị 0 –> vô dụng.
- CutMix thay vùng ảnh bị loại bỏ bằng một phần ảnh của ảnh khác trong dataset.
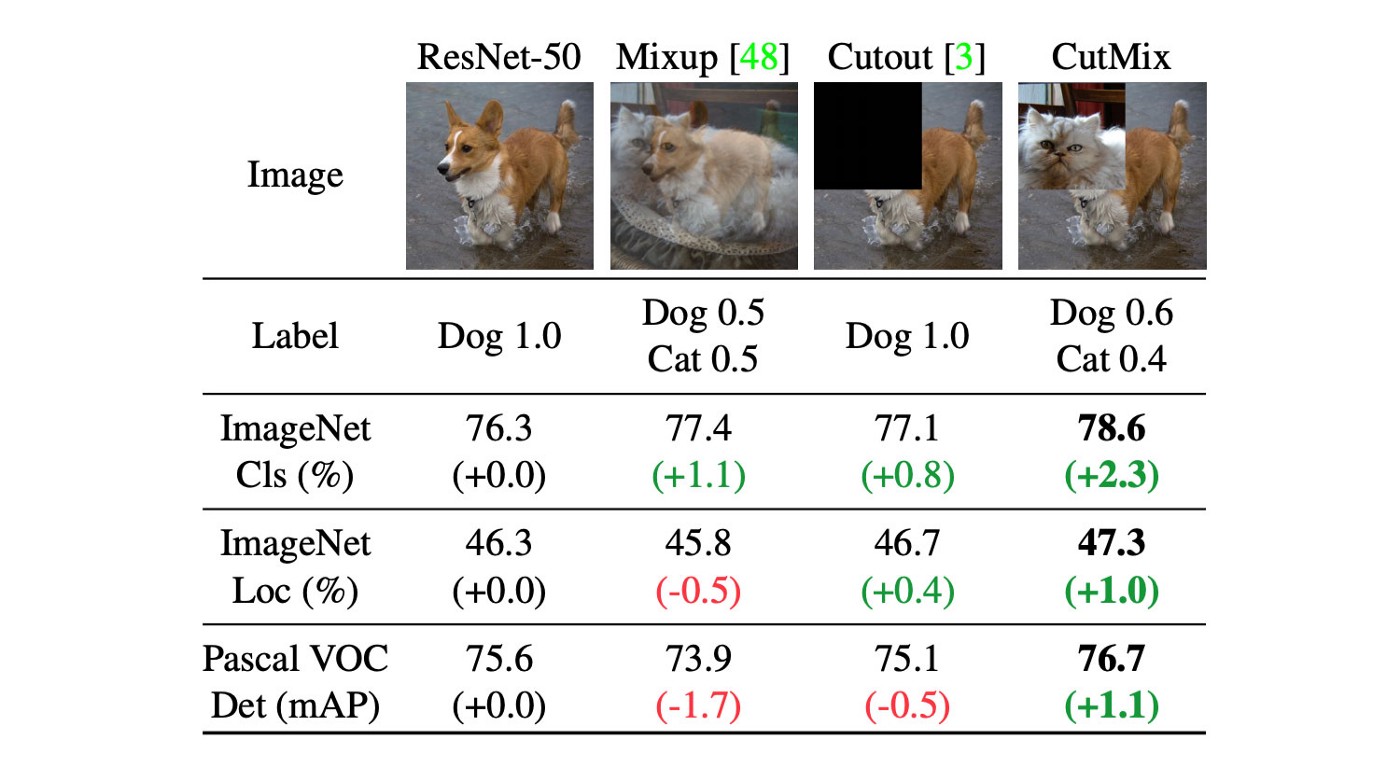
- Vùng bị thay thế này sẽ bắt buộc object classification học với nhiều loại feature.
2. Mosaic data augmentation
- Thay vì mỗi input image là sự kết hợp của 2 ảnh thì Mosaic sử dụng kết hợp 4 ảnh. Việc này giúp cho context của ảnh phong phú hơn.

3. DropBlock regularization
- Trong Dropout, hypothesys là các điểm gần nhau thường có đặc điểm giống nhau, do đó ta có thể loại bỏ các điểm này bằng cách set weight=0 tại một số vị trí trên feature map.
- Trong DropBlock, các vị trí được chọn không phân bố ngẫu nhiên nữa mà tập trung thành các block.
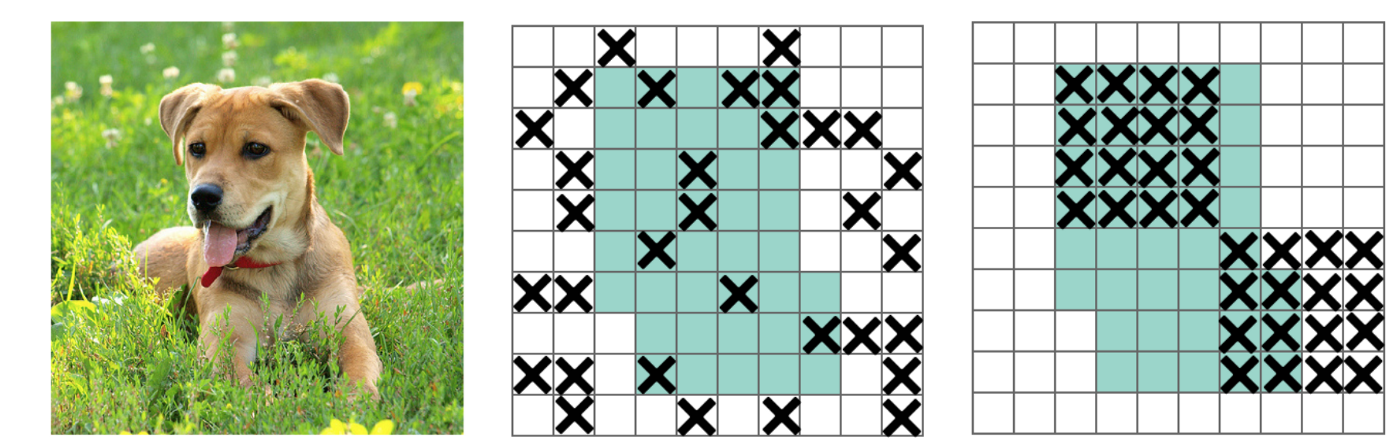
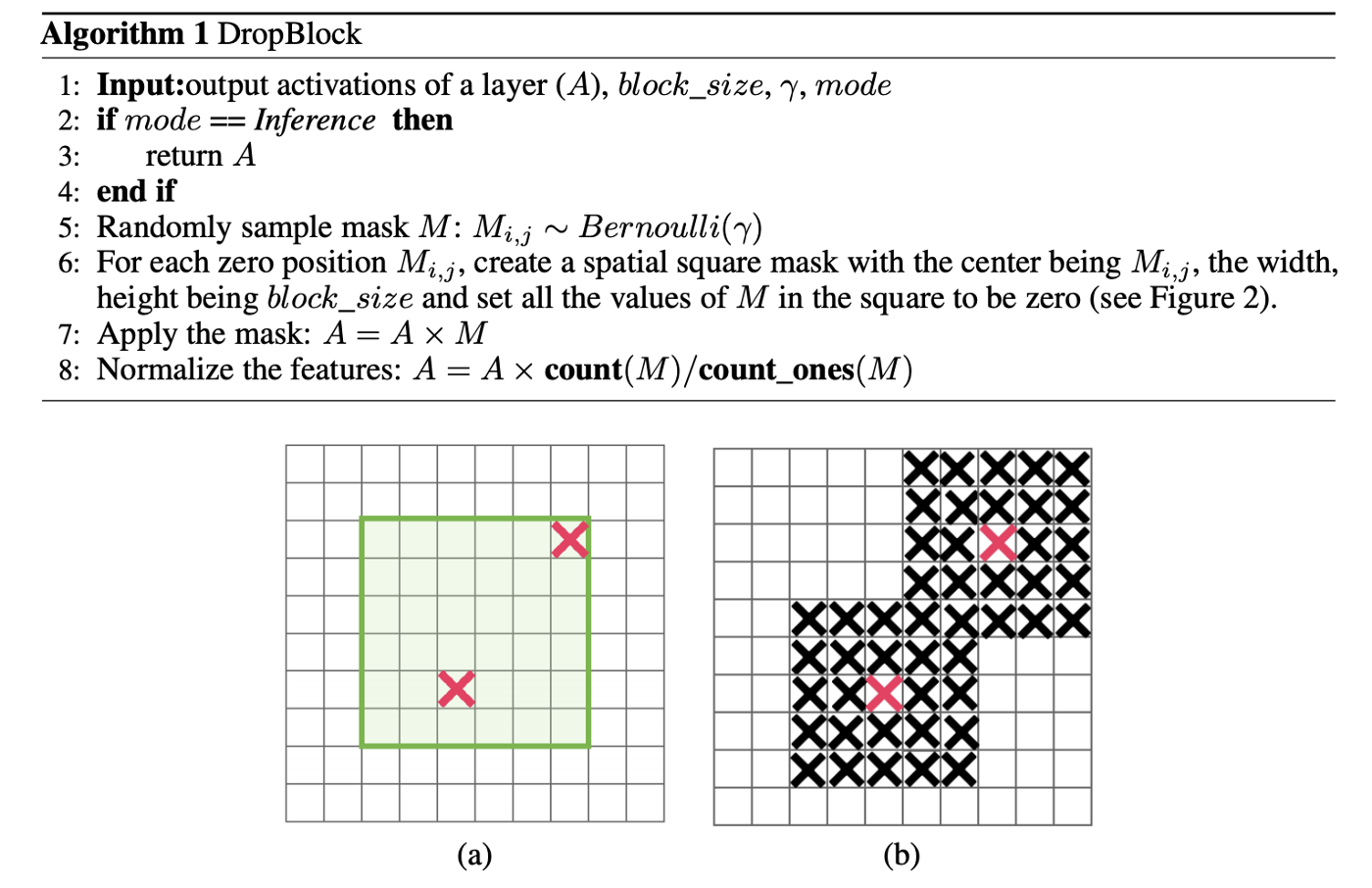
4. Class label smoothing
- Thay giá trị 1.0 –> 0.9 trong one-hot coding. Điều này giúp ta ngay cả khi đoán đúng class của một bức ảnh thì vẫn có loss. Do đó model sẽ phải điều chỉnh trọng số, giúp tránh việc overconfident vào kết quả dự đoán của mình –> tránh bị overfitting.

Bag of Specials (BoS) cho backbone
- Yolov4 sử dụng các phương pháp BoS sau cho backbone:
- Mish activation,
- Cross-stage partial connections (CSP), and
- Multi-input weighted residual connections (MiWRC)
- Vì Yolov4 sử dụng backbone là CSPDarknet53, ta xem qua mô hình Darknet53 để hình dung rõ hơn sự cải tiến.
1. Mish activation
- Mới được công bố tháng 8/2019.
- Theo tác giả, sử dụng Mish thu được kết quả tốt hơn so với ReLu, SoftPlus, Swish cũng như một số activation function khác (Adam, Ranger, RangerLars, Novograd, …)
![]()
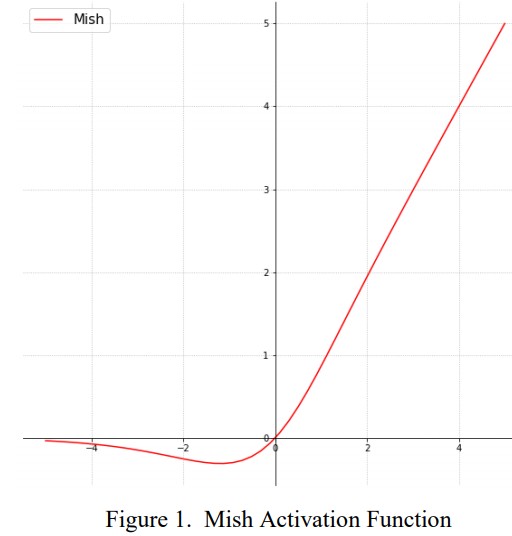
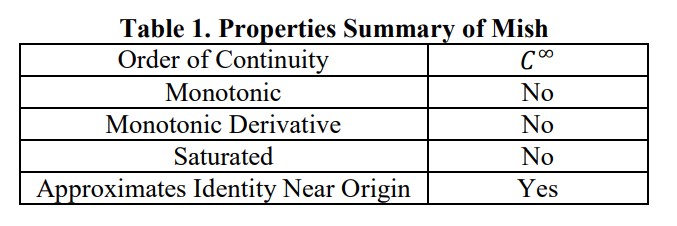
- Value range: -0.31 –> inf
- Một số thuộc tính quan trọng của Mish:
- Không có cận trên
- Có cận dưới
- Không đơn điệu, giữ lại một phần nhỏ negative gradient cho phép model học tốt hơn (vd: ReLu không cho phép gradient âm).
- Liên tục: Mish có đạo hàm bậc 1 tại mọi điểm thuộc miền giá trị (so sánh với ReLu không có đạo hàm tạo x=0)
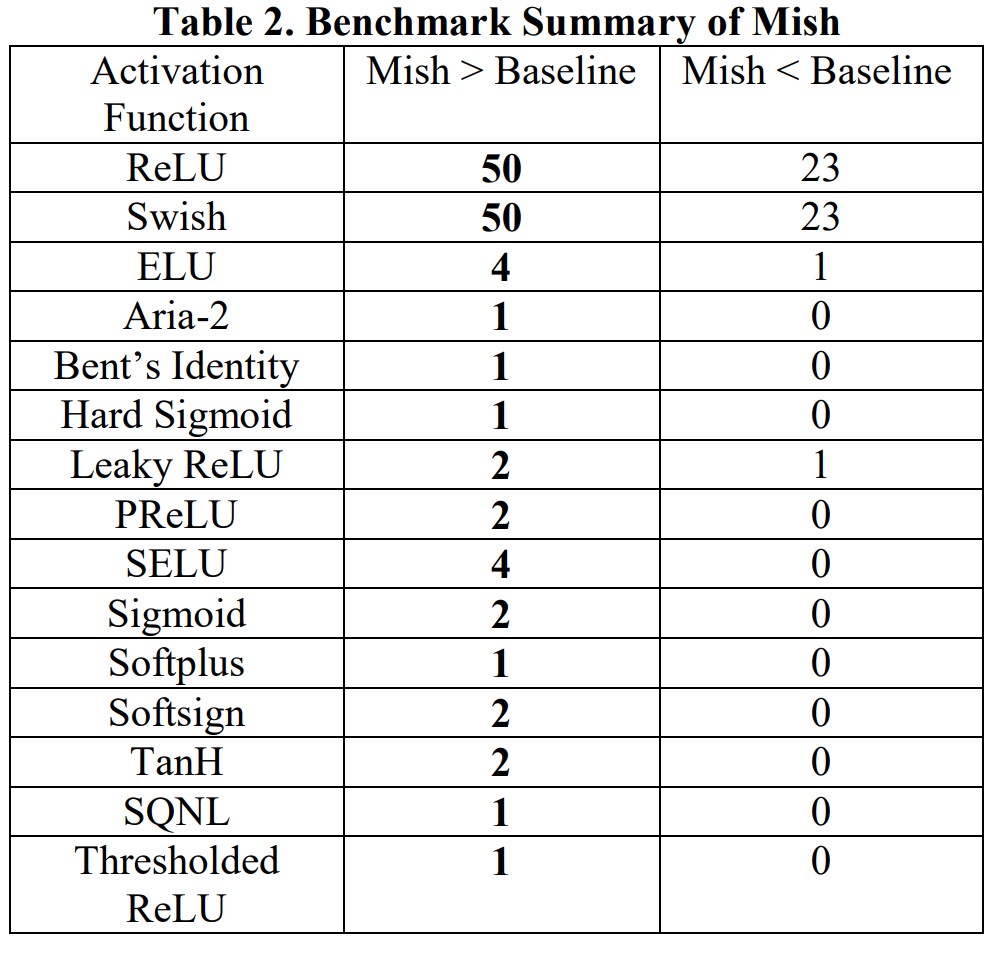
- So sánh Mish với Swish và ReLu
- (Tại sao Mish tốt hơn các activation khác?)
- Allow small negative gradient
- Mish smooth hơn các activation khác –> giúp truyền tải thông tin xuống các lớp sâu hơn trong neural network dễ dàng hơn –> tăng accuracy, generalization.

From the paper- a comparison of the output landscape from ReLU, Swish and Mish. The smooth gradients from Mish is a likely driver of it’s outperformance.
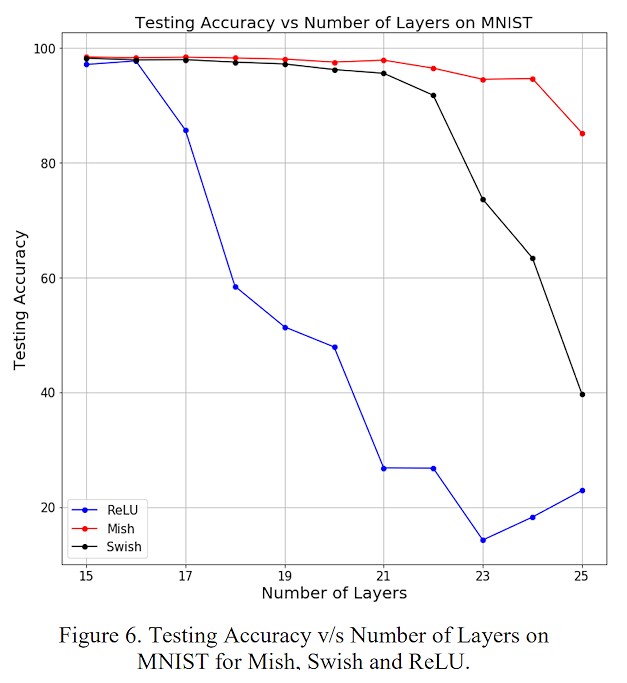
- Tính smooth của Mish được thể hiện bằng cách tăng số lượng hidden layer của network, đo độ chính xác của mô hình khi sử dụng ReLu/Swish/Mish. Ta có thể thấy performance của Mish không bị giảm quá nhiều khi tăng số lượng layer như đối với ReLu và Swish.
- More infomations: link, paper, link
2. Cross-stage partial connections (CSP) – [Xem bên trên]
3. Multi-input weighted residual connections (MiWRC)
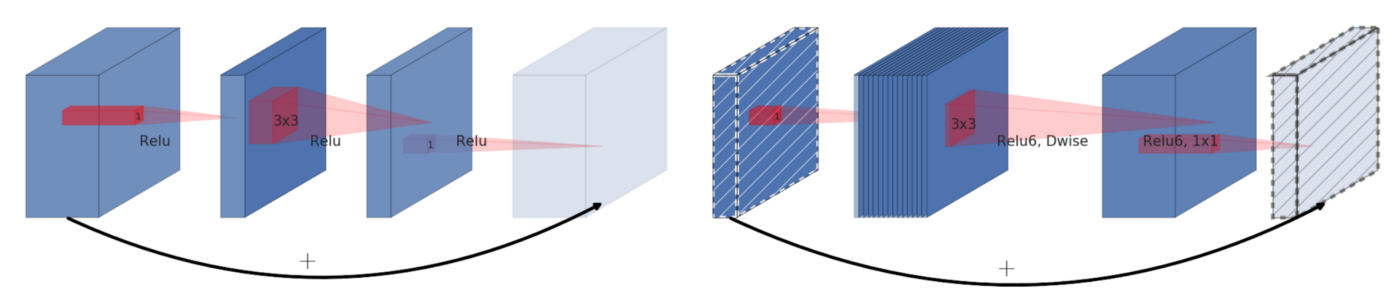
- Invert Residual Block:

-
- Được sử dụng đầu tiên trong MobleNetv2
- Trong khi số lượng channel trong Residual block là wide->narrow->wide thì số lượng channel trong Invert Residual Block là narrow->wide->narrow. Ý tưởng ở đây là 1) khi áp dụng khối conv 1×1 nên sử dụng linear activation ; 2) nên tạo skip-connection giữa các lớp low-dimentional feature maps (narrow) –> deepwise conv .
-
- Linear activation giúp tránh mất mát dữ liệu khi đi qua khối 1×1 conv.
- Deepwise Conv giúp giảm khối lượng tính toán cần thực hiện.
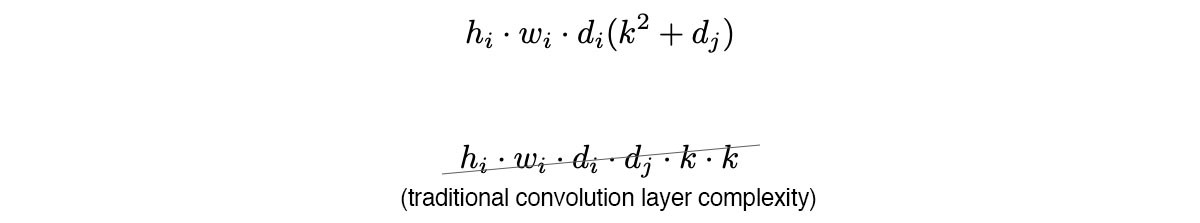
-
- Ngoài ra, Invert Residual Block còn sử dụng ReLu6. ReLu6 giới hạn phần nguyên của số float thuộc [0, 6] giúp ta có thể biểu diễn phần số phẩy động tốt hơn trong khi sử dụng ít bits hơn để biểu diễn weights trong mạng (ví dụ sử dụng float8).
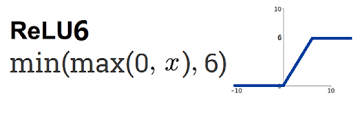
- Multi-input weighted residual connections
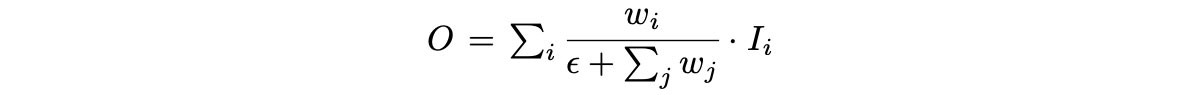
-
- Trong đó, wᵢ sẽ được train như các trainable parameter khác.
Bag of Freebies (BoF) for detector
- Yolov4 sử dụng các BoF sau cho detector:
- CIoU-loss,
- CmBN,
- DropBlock regularization,
- Mosaic data augmentation,
- Self-Adversarial Training,
- Eliminate grid sensitivity,
- Using multiple anchors for a single ground truth,
- Cosine annealing scheduler,
- Optimal hyperparameters, and
- Random training shapes
1. CIoU-loss
- Để cập nhật trọng số cho mô hình, các phương pháp object detection thường dùng hàm loss là IoU
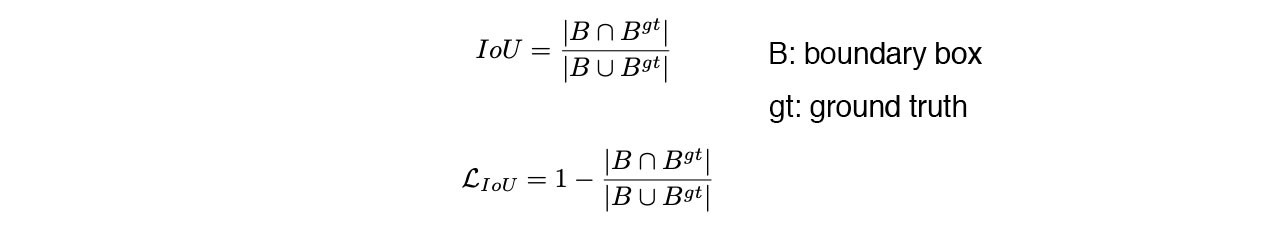
- Tuy nhiên, khi ta sử dụng IoU, xét 2 trường hợp prediction bounding box và groundtruth bounding box không overlapping, ta không thể nói trường hợp nào tốt hơn trường hợp nào, do đó gây khó khăn cho việc cập nhật trọng số theo hướng khiến prediction bbox tiến gần tới groundtruth bbox.
- GIoU giải quyết điều này bằng cách thêm vào IoU một thành phần C: bbox nhỏ nhất mà chứa cả prediction bbox và groundtruth bbox (xem như khoảng cách giữa 2 bbox này).
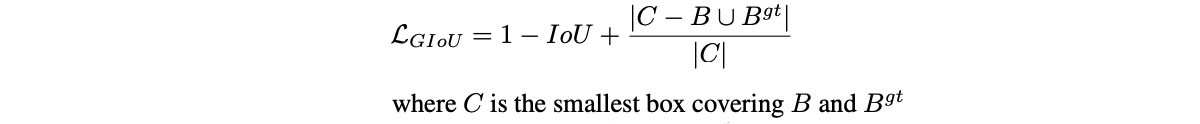
- Tuy nhiên, khi sử dụng GIoU lại có một vấn đề là mô hình có khuynh hướng mở rộng prediction bbox trước cho tới khi nó overlapping với groundtruth, sau đó mới co lại để giảm IoU.
- DIoU giải quyết được vấn đề này bằng cách không chỉ đưa bbox C vào ràng buộc mà còn đưa khoảng cách giữa tâm của prediction bbox và tâm của groundtruth bbox. Bây giờ, thành phần c ở mẫu chỉ đóng vai trò chuẩn hóa khoảng cách giữa 2 tâm của prediction bbox và groundtruth bbox (???).

- Cuối cùng, CIoU đưa thêm vào tham số giúp duy trì tỷ lệ của các bbox.

2. CmBN
- Batch Normalization collects mean and variance of the sample within mini-batch to normalize the input. However, if mini-batch is small, then these estimation will be noisy. One solution is to estimate them among many mini-batches.
- Batch Normalization tính toán mean và variance của các mẫu trong một mini-batch để chuẩn hóa đầu vào. Tuy nhiên, nếu mini-batch nhỏ, các ước lượng này sẽ bị nhiễu. Một giải pháp là ước lượng mean và variance dựa trên nhiều mini-batch. Tuy nhiên, do weights thay đổi mỗi iteration, việc tính trung bình một cách đơn thuần sẽ dẫn tới kết quả sai.
- Cross-Iteration Batch Normalization (CBN) ra đời để giải quyết vấn đề trên. Trong đó, mean, variance tại iteration hiện tại sẽ được tính dựa trên k iteration gần nhất.
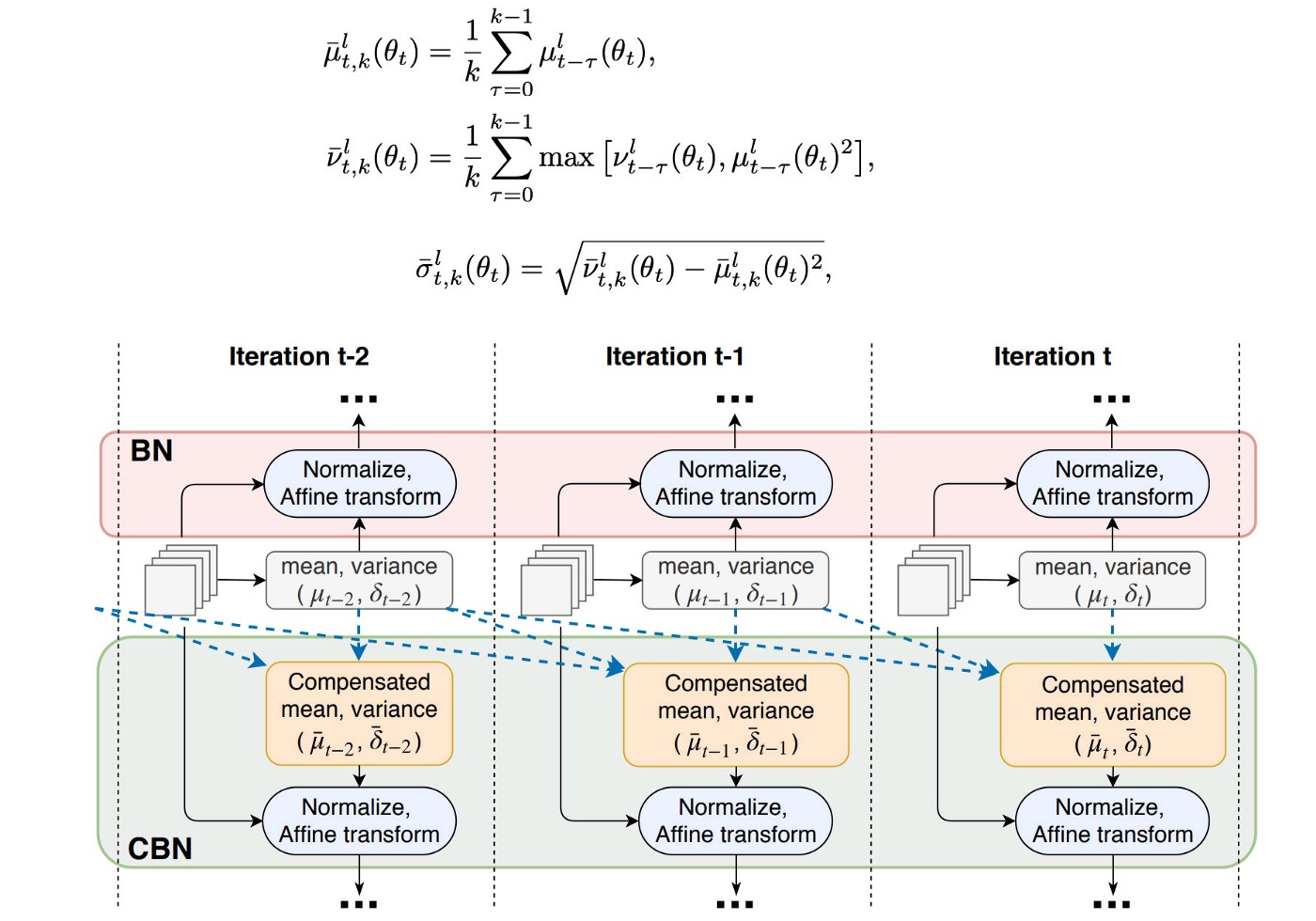
- CmBN thay đổi một chút so với CBN: tính các tham số trên dựa trên các mini-batch trong cùng một batch.
3. DropBlock regularization
4. Mosaic data augmentation
5. Self-Adversarial Training
- Là một phương pháp data augmentation. Trong data augmentation, ta muốn tạo từ ảnh gốc các ảnh mới gây khó khăn cho network để network thực sự hiểu và học được cách phân biệt các object khác nhau trong ảnh (ví dụ phương pháp thêm nhiễu, mosaic, cutmix, …).
- Bao gồm 2 phase forward-backward propagation.
- Phase forward-backward 1: model thực hiện forward propagation như bình thường. Sau đó, thay vì điều chỉnh weights của model, ta thay đổi input images để làm cho model có kết quả tồi đi theo hướng network không thể phát hiện được các object trong ảnh nữa. (bước này tương tự như thêm nhiễu vào ảnh nhưng theo tác giả có hiệu quả tốt hơn).
- Phase forward-backward 2: Sử dụng các ảnh mới được tạo ra để training model như bình thường, sử dụng các grounthtruth bbox và label của ảnh gốc. (Ở đây có thể sử dụng bbox và label cũ bởi vì kích thước và vị trí của các object trong ảnh mới không thay đổi do ảnh mới được tạo thành bằng cách thay đổi giá trị pixel của ảnh cũ).
- Xem thêm tại đây
6. Eliminate grid sensitivity
- Do sử dụng hàm sigmoid nên để b(x) = c(x) hoặc b(x) = c(x) + 1 thì giá trị tuyệt đối của t(x) phải rất lớn. Để giải quyết vấn đề này, các tác giả cho thêm một hệ số scaling (>1.0):

7. Using multiple anchors for a single ground truth
- Use multiple anchors for a single ground truth if IoU(ground truth, anchor) > IoU threshold. (Note, not enough information for me in determining its role in YOLOv4 yet.)
8. Cosine annealing scheduler
- Giảm learning rate theo hàm cosine. Bắt đầu giảm chậm, sau đó giảm nhanh, sau lại giảm chậm, …
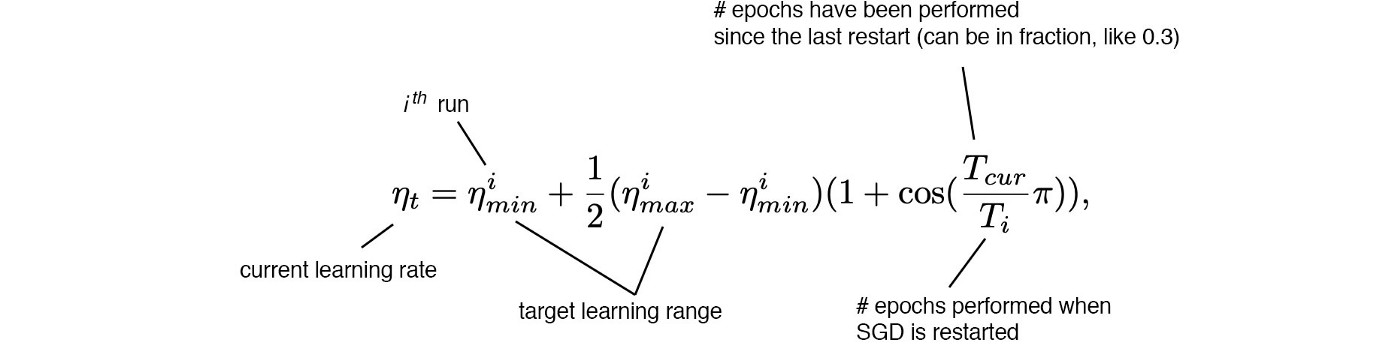
- Tác dụng của phương pháp này so với learning rate decay không rõ ràng lắm.
9. Optimal hyperparameters
- Sử dụng giải thuật di truyền (GA) để tìm optimal hyperparameters
10. Random training shapes
- Training model với kích thước input image khác nhau.
Bag of Specials (BoS) for detector
- The BoS features for YOLOv4 detector include:
- Mish activation
- modified SPP-block
- modified SAM-block
- modified PAN path-aggregation block
- DIoU-NMS
- Mish activation (bên trên)
- modified SPP-block (bên trên)
- modified SAM-block (bên trên)
- modified PAN path-aggregation block (bên trên)
- DIoU-NMS
- NMS lọc ra các prediction bounding box cho cùng một object và chỉ lấy bbox có confident cao nhất. Confident ở đây được đo bằng IoU

- DIoU-NMS có thay đổi một chút là confident được đo bằng DIoU.
Reference
- https://medium.com/@jonathan_hui/yolov4-c9901eaa8e61
- https://arxiv.org/pdf/2004.10934.pdf
- https://medium.com/@arthur_ouaknine/review-of-deep-learning-algorithms-for-image-semantic-segmentation-509a600f7b57
- https://medium.com/@lessw/meet-mish-new-state-of-the-art-ai-activation-function-the-successor-to-relu-846a6d93471f
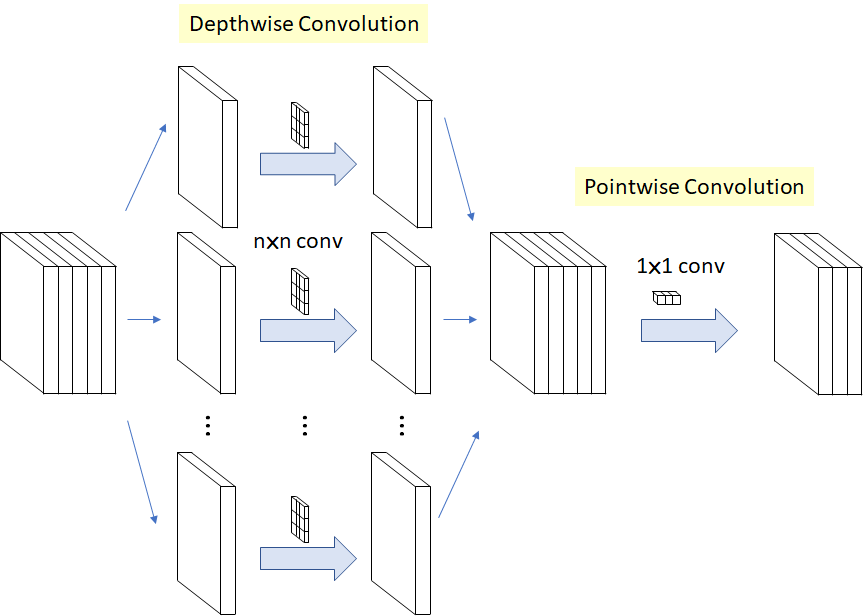
- https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
- https://github.com/AlexeyAB/darknet/issues/5117

Cho mình hỏi, inference và tốc độ inference trong bài này được hiểu là gì nhỉ. Tks bạn
LikeLike
inference ở đây là cho một bức ảnh đầu vào và predict bounding box của nó bạn nhé. inference speed là tốc độ mà mô hình dự đoán, tức là mô hình dự đoán được bao nhiêu bức ảnh trong một giây.
LikeLiked by 2 people
Bạn ơi cho mình hỏi về phần Self-Adversarial Training, tại sao mô hình lại train input image mới với ground truth cũ được vậy bạn?
LikeLiked by 1 person
Cảm ơn bạn đã đặt câu hỏi. Mình có update lại phần SAT cho đọc dễ hiểu hơn rồi nhé.
Ở đây có thể sử dụng bbox và label cũ bởi vì kích thước và vị trí của các object trong ảnh mới không thay đổi do ảnh mới được tạo thành bằng cách thay đổi giá trị pixel của ảnh cũ
LikeLiked by 1 person